
This framework aligns with Google’s official guidance: optimizing for generative AI search is optimizing for the search experience and thus remains rooted in foundational SEO best practices. (Google Search Central).
We use “GEO” as a shorthand for citation-specific tactics within SEO, not as a replacement for the discipline. All recommendations below are rooted in Google’s foundational SEO guidance. Google provides principles, not a citation model. The three-layer framework below, Memory, Retrieval, and Citation, is an operational model derived from observed behavior across AI systems, not an official Google classification.
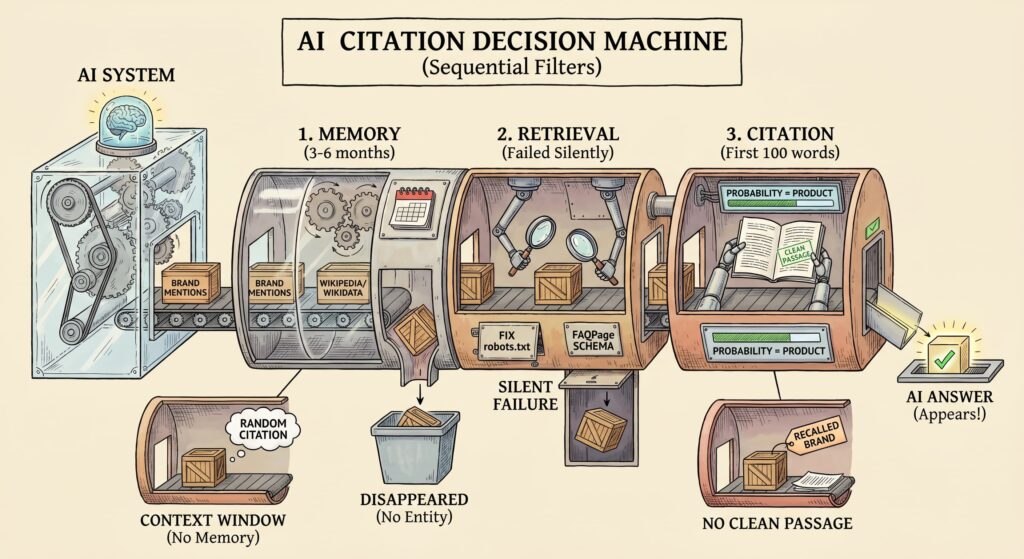
AI systems decide which brands to cite based on three sequential filters: memory, retrieval, and citation quality. The probability of appearing in an AI answer is their product; if one layer fails, your brand may not be cited in AI-generated answers, even with otherwise strong SEO fundamentals. This article explains each filter and the specific signals you can engineer today.
TL;DR: AI citations work like a three-step funnel. If one step breaks, your brand may not be cited in AI-generated answers, even with otherwise strong SEO fundamentals.
- Memory (3–6 months): Does the AI actually know you? Build that through consistent brand mentions across the web. Wikipedia and Wikidata entries are widely used in GEO practice for entity recognition. Note this is an industry recommendation, not a Google requirement.
- Retrieval (the silent killer): Can the AI find you? Most brands fail here without realizing it. Start with crawlability and clear content structure. Schema is not a factor in Google’s AI retrieval but remains useful for rich results eligibility.
- Citation (first 100 words): Once found, can the AI quote you? Put the clearest answer at the very top. AI retrieval systems extract passages programmatically, but your content must first satisfy human readers. Clear structure serves people; extraction is a side effect.
The two classic traps:
- Good retrieval, weak memory: Your page lands in the AI’s context window, but the model has no idea who you are. You get a random, one-off mention that never repeats.
- Strong memory, messy content: The AI remembers your brand but can’t find a clean passage to quote. You exist in its head but never make it into the answer.
Fix all three layers, or you’ll stay invisible.
In our previous article, we mapped the shift from search rankings to AI selection: why the funnel is collapsing and what buyers now see instead of blue links. Here we go one level deeper into the mechanics of how AI systems actually decide which brands to cite and the specific signals you can engineer.
The Three Filters Every Source Must Pass
AI citations are shaped by three sequential filters:
Memory: Does the model know the brand from training data?
Retrieval: Can the system find and fetch the source in real time?
Citation: Once retrieved, is the content structured cleanly enough to quote?
The probability of citation is their product:
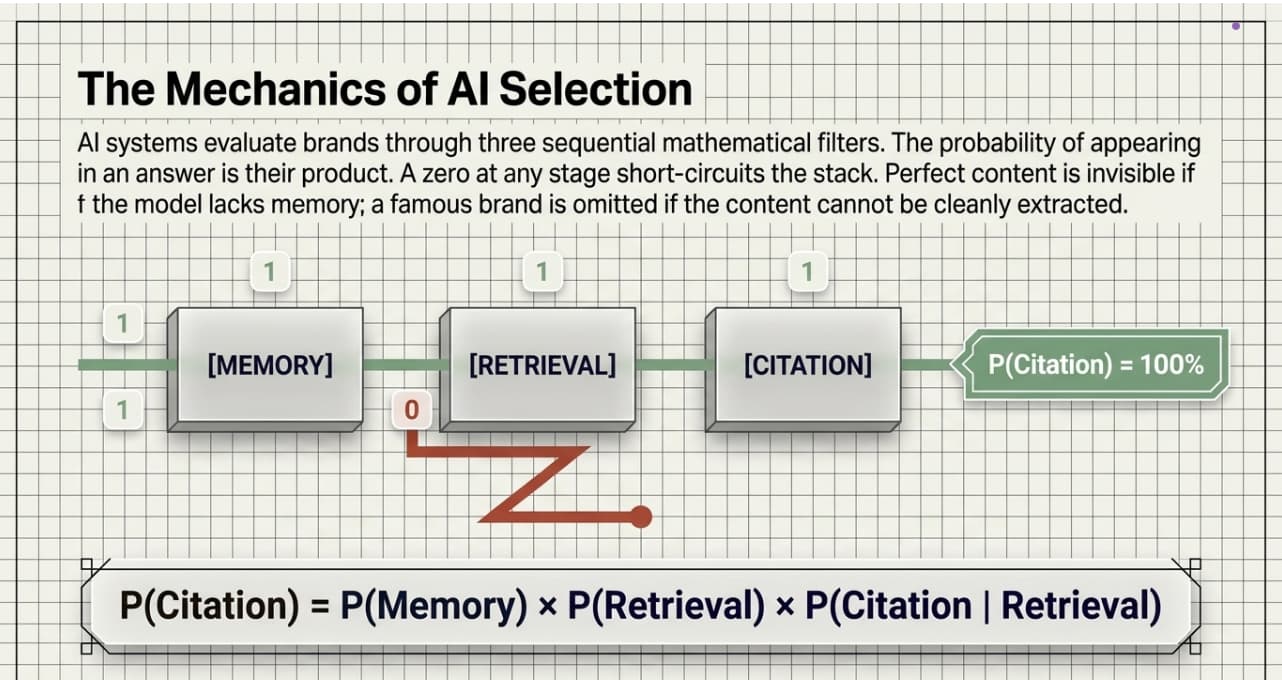
Citation Likelihood ≈ Memory × Retrieval × Extractability
This is a heuristic framework for prioritization, not a proven probabilistic formula. If one layer is weak, the chance of being cited drops sharply.
This model is especially useful for RAG-based systems, Perplexity, Gemini with search, and ChatGPT when browsing is enabled. In these systems, source documents are injected into the context window before generation begins. In practice, the model can only cite what retrieval makes available. Offline parametric models operate differently, recalling from training weights with no live citations, but for commercial AI search visibility, RAG-based retrieval is the dominant operational model.
AI answers usually cite only a small number of sources, which makes extractable passages more important than broad page-level visibility. The real competition is no longer just the article itself but the most extractable passage available for that question.
What Each Platform Actually Weighs
The same three filters apply across all major AI engines. However, each system assigns different weights to memory, retrieval, and citation quality, and this divergence is often underestimated in most GEO frameworks.
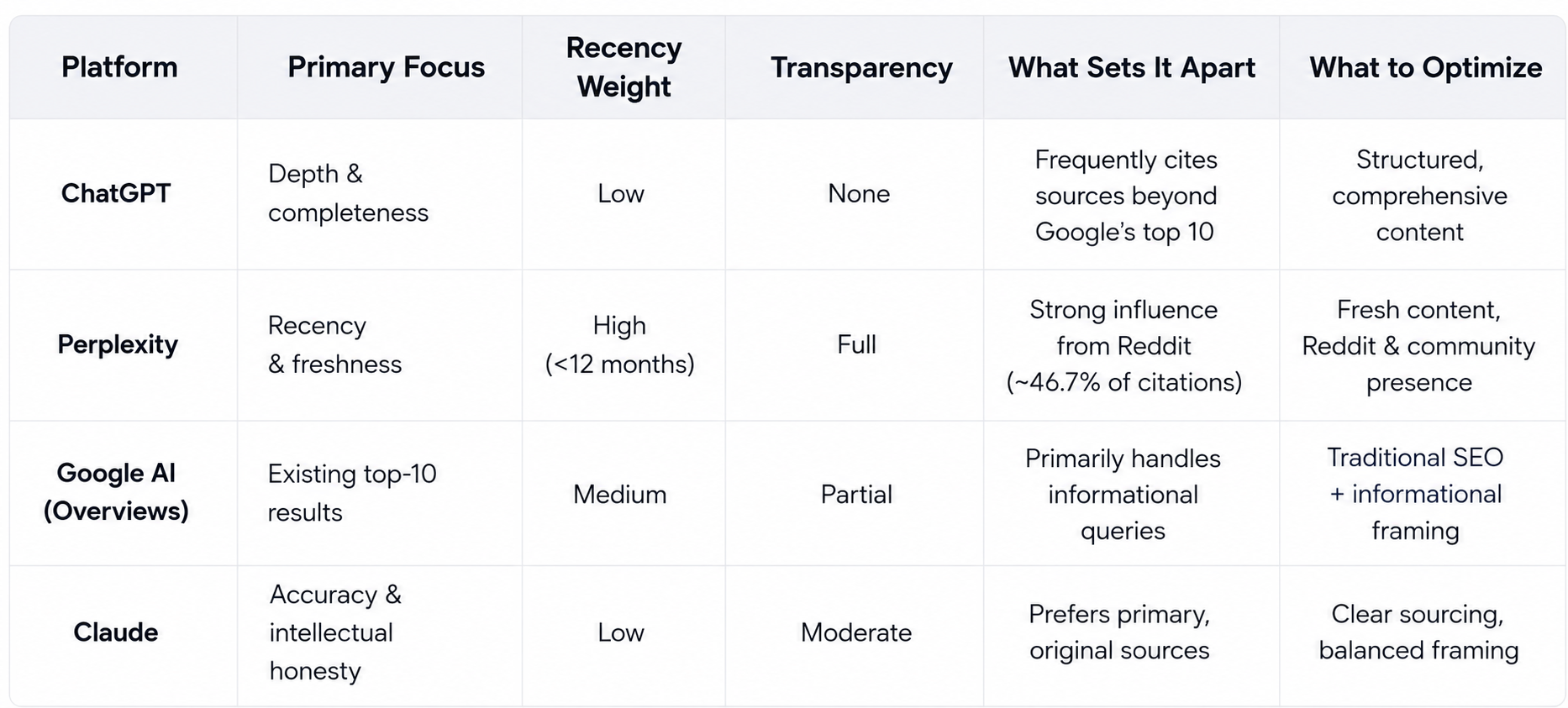
The practical gap between platforms is extreme and often underestimated. Grok tends to cite sources far more aggressively than Claude, which rarely provides URLs at all. Gemini frequently references URLs without ever speaking the brand name, a phenomenon known as “ghost citations.” Perplexity shows 76.9% positive sentiment in citations; ChatGPT shows 6.8% (Source: Searchable AI Visibility Report, 2026).
These divergent profiles mean your strategy must be platform-specific. What wins on Perplexity may be invisible on Claude.
Perplexity is the most socially driven system. Reddit dominates its list of top-cited domains, accounting for 46.7% of the most frequently referenced sources (Source: Searchable, 2026). This makes community-generated content a core input signal rather than a secondary one.
For B2B, niche communities (e.g., r/marketing, r/saas) function as high-weight expert signals that are frequently surfaced in responses.
In this context, Reddit is not “social media”; it behaves more like a distributed knowledge layer. Structured data can improve extractability and rich results eligibility, but Google’s generative AI features do not require it; their systems understand page content without special markup. (Google). (For vertical-specific lift data, see your platform’s Search Console and GA4 AI referral segment.)
This is why the content philosophy from our previous article on AI-driven search strategies matters so much. AI retrieval systems tend to extract early, clearly structured passages. This does not mean long-form content is penalized — Google explicitly states there is no ideal page length. Comprehensive coverage remains valuable when well-organized for human readers. (Google)
Engineering the Stack → Memory
Memory builds from training data and entity graph density. Brand search volume consistently emerges as the strongest predictor of AI visibility, stronger than backlink count or domain authority alone. If buyers are not already searching your brand name, AI systems have weak entity signals to recall. This happens partly because of query fan-out: AI search engines decompose each user prompt into multiple sub-queries before synthesizing an answer.
Your brand needs to surface across several of them to be cited, which is why mentions across independent platforms matter more than depth on any single one.
Entity authority appears to outweigh SERP position in observed citation data. Forbes ranks #1 for “best CRM” and gets cited by ChatGPT; PCMag ranks #2 and gets ignored. Based on external research, the likely differentiator is entity graph density. This is an observed pattern, not confirmed by Google. AI engines cite the brand they recognize, not the page that ranks highest.
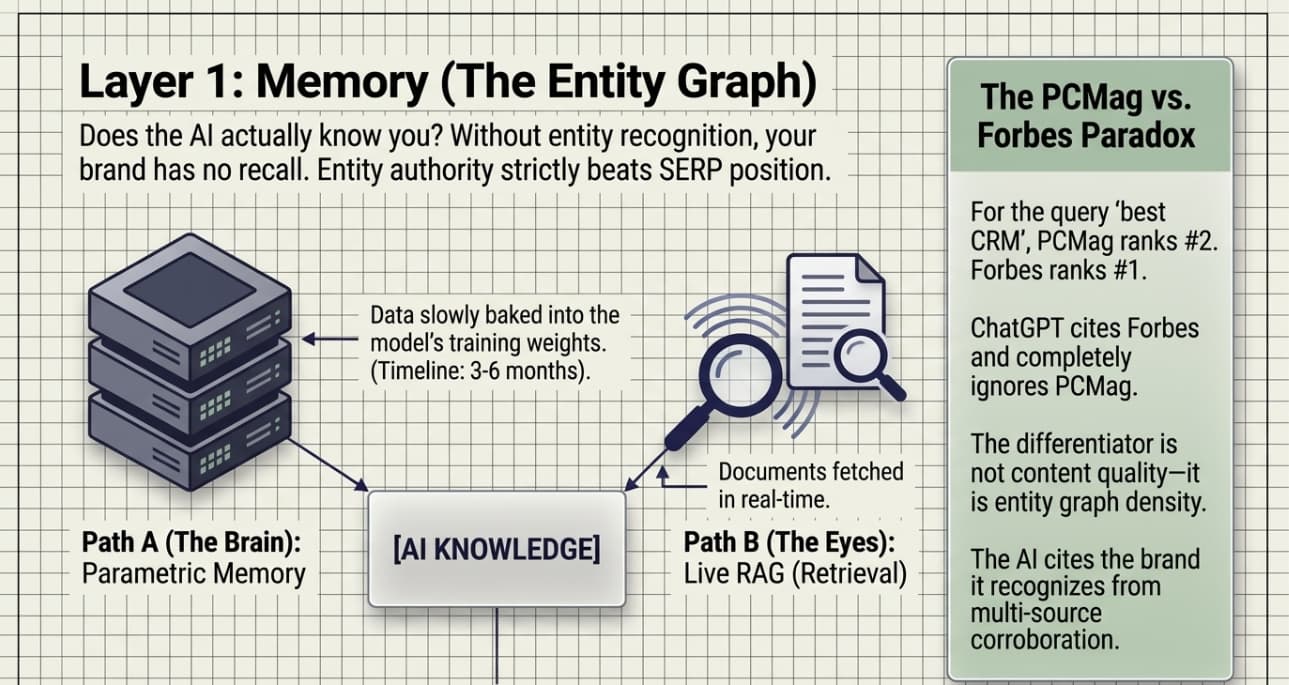
Geographic bias adds another layer of complexity. US-based brands are cited more frequently than non-US brands across major AI engines, largely because training data and retrieval indexes skew toward English-language, US-centric sources. If your primary market is outside the United States, your GEO strategy requires stronger entity signals, Wikipedia, Wikidata, and region-specific review platforms to compensate for this structural disadvantage.
Timeline: 3–6 months for new brands; established brands rarely bottleneck here.
The problem is that inconsistent brand descriptions across LinkedIn, Crunchbase, your About page, and coverage create conflicting entity signals, reducing the model’s confidence in your brand identity.
The fix:
Your own site accounts for roughly 9% of AI-generated brand mentions. The remaining 91% comes from review platforms, Reddit, industry publications, and forums, sources you don’t control (Source: topify.ai, 2026). No amount of on-site optimization captures that gap.
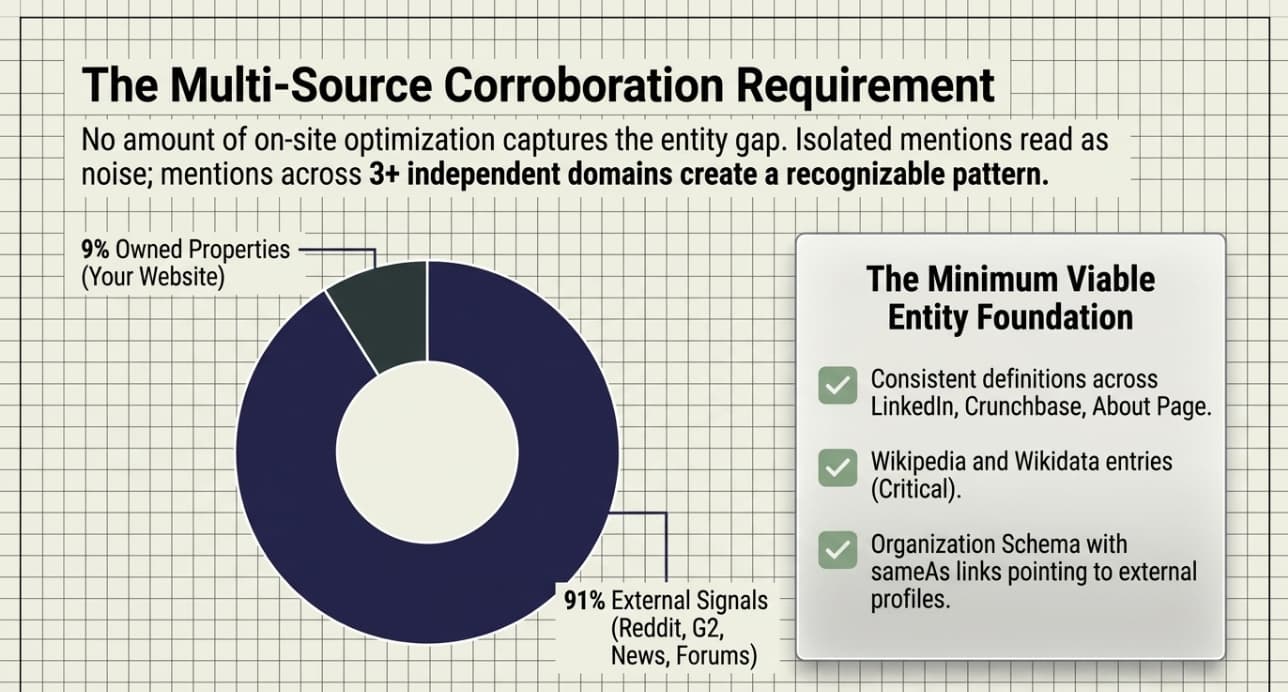
Earn consistent, organic external mentions across 4+ independent platforms. These must be authentic signals; Google’s spam systems actively deprioritize inauthentic mentions and paid placements. (Google).
Cross-platform presence appears to be a strong predictor of AI citation rates in observed datasets, often outweighing raw backlink volume alone. In practice, AI engines appear to apply multi-source corroboration: mentions in three or more independent domains create a recognizable pattern, while isolated mentions read as noise.
Create or claim Wikipedia and Wikidata entries. Based on industry practice and GEO community research, these are widely recommended foundations for entity recognition. Note that Google’s official guidance focuses on Google Business Profiles and on-site entity clarity rather than Wikipedia specifically.
Synchronize entity definitions everywhere (identical category, value prop).
Add an organization schema with sameAs links pointing to Wikipedia, Crunchbase, LinkedIn, and G2. Memory is typically the slowest layer to build; once established, it also tends to be the most durable.
Retrieval: The Primary Bottleneck
In our observed data, retrieval is where most brands silently fail. Google does not classify failures this way, but the pattern appears consistently across RAG-based platforms. Perfect content is invisible if it never enters the context window.
Most brands handle robots.txt incorrectly. GPTBot and Google‑Extended ingest content to build parametric memory during model training, while Perplexity relies heavily on real-time retrieval.
For GPTBot, the decision is strategic. Blocking it may reduce future parametric citations, but it does not affect current live-search citations.
Note the distinction: only about 11% of cited domains overlap between ChatGPT and Perplexity (Source: Averi analysis of 680M citations, March 2026).
But an even sharper decoupling is happening inside Google itself: a February 2026 Ahrefs study of 863,000 keywords found that only 38% of pages cited in AI Overviews also rank in the top 10 for the same query, down from 76% just seven months earlier (Source: Ahrefs, February 2026). You can now earn AI citations without a top-10 ranking, and you can lose them despite ranking #1.
A brand visible on one platform may be invisible on the other. Retrieval optimization is platform-specific, not universal. The long-term ROI remains uncertain, which is why most brands still allow access. The real question is whether you want your content included in future GPT-trained models.
Schema markup improves rich results and content extractability. While not required specifically for Google’s generative AI features, it remains a foundational SEO best practice with secondary benefits for AI retrieval systems. (Google).
The larger gains come from combining schema with BLUF structure, semantic HTML, and regularly refreshed content. Exact percentage gains vary by vertical. Structured data improves extractability and eligibility for rich results but is not required for Google’s generative AI features.
One underused retrieval signal: YouTube. Video content is gaining citation share on both Perplexity and Google AI Overviews, a meaningful signal for brands investing in video as part of their content strategy.
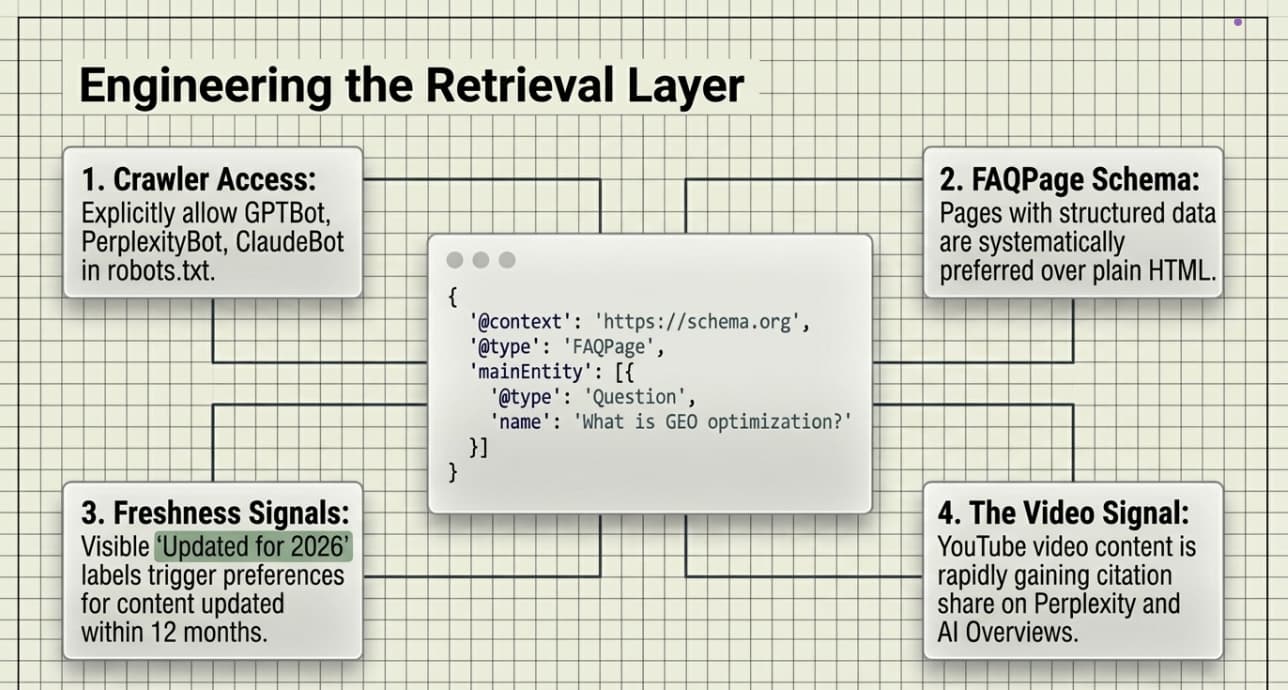
Most impactful schema for GEO:
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [{
“@type”: “Question”,
“name”: “What is GEO optimization?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “GEO (Generative Engine Optimization) is the practice of optimizing content to be cited by AI search engines, including ChatGPT, Perplexity, Google AI Overviews, and Claude.”
}
}]
}
Also critical: semantic HTML, clean headings, a valid sitemap.xml, page speed under 2s, and regular content refresh. Freshness appears to influence AI retrieval: content with prominent freshness signals, such as a visible “Updated for 2026” label, frequently outperforms stale pages in AI responses. Perplexity shows a strong preference for recent content, frequently surfacing pages updated within the last 12 months.
Citation: The Passage-Level Decision
Citation happens at the passage level, not the page level. AI favors the earlier, more extractable parts; your intro is where the decision is made.
According to the Princeton GEO study (Aggarwal et al., KDD 2024), content structured for easy extraction outperforms unstructured prose by up to 40% in AI visibility, and pages where answers appear within the first 100 words are cited significantly more often. Note: This is external research, not a Google recommendation.
AI Overviews favor passages of roughly 130–170 words, with the majority of featured content falling between 100 and 300 words. Including specific statistics with clear source attribution throughout your content improves extractability and citation likelihood. Comprehensive, topic-depth coverage that naturally addresses related questions within a single resource tends to surface across fan-out queries — not because it targets them, but because it genuinely covers the subject. Creating thin, scaled content for query variations violates Google’s scaled content abuse policy. (Google)
What makes content citable vs what kills extractability
| Makes content citable | Reduces extractability |
|---|---|
| Specific, quotable claims | Dense prose without structure or breaks |
| BLUF (answer placed within first 100 words) | Long introductions that bury the main point |
| Clear provenance (author, date, attribution) | Vague positioning (“our tool is great,” “we help businesses”) |
| Comparison tables and structured formats | Overly narrative, paragraph-only explanations |
| Original data, insights, or research | No unique information or derivative summaries |
| Direct, declarative language | Excessive hedging (“might”, “possibly”, “could be”) |
| Early positioning (answer in the first 2 sentences dramatically increases citation likelihood) | The answer is buried after 300+ words |

In practice, AI systems favor sources that align with E-E-A-T signals.
AI systems evaluate experience, expertise, authoritativeness, and trustworthiness before citing a source. An author bio with relevant credentials increases citation probability; anonymous or unattributed content is less likely to be cited, as AI systems weigh provenance and author credibility heavily.
Third-party validation matters more than self-claimed expertise: when independent publications cite your research, quote your founder, or reference your original data, AI systems weigh those signals significantly higher than on-site author bios alone. A LinkedIn profile or company About page stating “we are experts” carries less citation weight than a TechCrunch article or peer-reviewed study that demonstrates that expertise externally.
Three Ways Brands Break the Stack
These patterns represent documented failure modes with clear fixes.
The Invisible Incumbent.
A mid-market CRM platform with fifteen years of history, strong backlinks, and even a Wikipedia presence never appeared in AI-generated answers. Memory wasn’t the issue; retrieval was. Product pages were buried behind JavaScript, FAQ schema was missing, and the content was organized around features instead of buyer questions.
Citation signals were absent: Long brand narratives, no original research, and answers buried after 400-word introductions. After restructuring with BLUF answer blocks, FAQPage schema, and comparison tables, citation rates in this case improved within weeks to several months, depending on the platform and competitive saturation. Perplexity responds faster; Google AI Overviews take longer.
The Unknown Specialist: A specialized email deliverability tool with best-in-class technology but near-zero brand recognition. Memory was close to zero, but citation signals were strong once engineered. The company published quarterly benchmarks using the JSON-LD schema, targeted long-tail queries in a narrow vertical, and built topical authority through a comprehensive glossary. It ran a focused PR campaign targeting AI-cited publications. After six months, the brand appeared consistently in AI responses for specialized deliverability queries. Strong citation signals in a narrow vertical compensate for weak memory. When you’re the only citable source in a narrow vertical, AI systems are far more likely to surface your brand.
The Over-Optimized Publisher: A B2B media site publishing hundreds of SEO-optimized articles monthly had strong traditional traffic but declining AI citation rates. Memory was strong. Retrieval was declining: keyword-stuffed, structurally generic content; no schema; and articles written for scroll depth rather than extraction. After reducing volume by half and restructuring for extractability (TL;DR summary boxes, original statistics, article schema, and FAQ sections appended to every pillar), AI citation rates recovered within three months. A volume optimized purely for keyword coverage may be less likely to earn AI citations if it lacks extractable depth and original insight. The site now publishes fewer articles, each engineered for the citation stack rather than the keyword list.
The Structured Educator: StackNova organized content around what engineers need to learn, not what SEO demands: clear learning paths, answers upfront, and semantic structure. It became the only citable source for its specific paths. Lesson: Structure for extraction first; citations follow.
Measuring GEO: KPIs That Actually Matter
Don’t track GEO like SEO. Rank trackers miss the point entirely. You need prompt-level monitoring across models.
✅ Primary metrics:
- Citation frequency: % of tracked prompts where you appear vs. competitors (GEO’s “keyword ranking”)
- Appearance rate: Cited at least once vs. never
- Trend velocity: Accelerating, stable, or declining? (Direction matters as much as position.)
- Authority rate: Primary source (early mention) vs. secondary (buried)
- Reuse Rate: When your brand does appear, is it described accurately? Track how consistently AI engines reproduce your core positioning across prompts. If ChatGPT calls you a “content marketing agency” when you’re actually a “fractional content strategist,” your structure is leaking. Define 3–5 core positioning statements and check whether AI reflects them. Perception drift is the gap between how you describe your brand and how an LLM summarizes it.
✅ Secondary metrics:
- AI-referred traffic: GA4 tracking for chatgpt.com, perplexity.ai, claude.ai, and gemini.google.com
- SERP Share of Voice: Count how many of the top 20 results for your core queries mention your brand. This is your AI visibility baseline and the metric that explains why ranking #1 is no longer sufficient. AI engines read snippets from all top results. If competitors dominate positions 2–10 through roundups, reviews, and forums, the AI cites them regardless of your position.
- Share of Model: the percentage of category queries where an LLM recommends your brand as a solution. This is the AI-era equivalent of market share. If you track only SERP positions, you are measuring the old battlefield.
- Zero-click baseline: AI Overviews now reduce position-one CTR by 58% (Source: Ahrefs, December 2025). The primary asset is no longer traffic from rank one; it is brand presence across the sources AI reads. Being referenced matters more than being clicked.
- Branded search spikes: Check Google Search Console after major AI citations appear. A rise in direct brand queries is often the earliest signal that GEO is compounding before referral volume becomes statistically significant.
- Citation sentiment: Monitor accuracy and tone. Entity consistency helps; negative training data citations are harder to fix.
- Ghost citation exposure: Many AI citations happen silently; the model references your URL without ever speaking your brand name. If you measure only explicit brand mentions, you miss most of your actual AI footprint. Track both: citation rate (URL referenced) and brand mention rate (name spoken). The gap between them is your ghost citation exposure.
✅ Monitoring cadence: Weekly minimum. Between 40% and 60% of cited sources change month to month as models update (Source: Semrush AI citation drift analysis, 2026). Quarterly reviews miss trends entirely.

Frequently Asked Questions
#1. If I block GPTBot today, do I lose citations immediately?
No, but the loss is delayed, not avoided. GPTBot builds parametric memory during model training, not live retrieval. Blocking it today won’t affect current Perplexity or ChatGPT browsing citations.
It may reduce the probability that future GPT model versions retain latent familiarity with your brand through training exposure. The strategic question is simple: Do you want your content to shape the next generation of models? Many brands currently allow access because the potential long-term visibility upside appears greater than the short-term data control benefit, though the causal relationship remains difficult to verify from outside OpenAI’s training pipeline.
#2. Perplexity cites Reddit in ~46% of cases. Do I need a branded Reddit presence?
You don’t need a corporate account; you need genuine community presence. Perplexity disproportionately cites Reddit because Reddit contains dense first-person problem-solving language, discussion depth, and continuously refreshed niche expertise. A corporate account posting promotional content will be ignored or downvoted, which actively hurts retrieval visibility.
What works: employees or founders participating authentically in r/marketing, r/saas, or your vertical’s primary subreddit. In practice, a single technically useful answer inside a high-intent thread often generates more retrieval visibility than months of branded posting.
#3. How do I isolate AI-referred traffic in GA4 exactly?
In GA4, AI referrals typically appear under standard referral traffic rather than organic search. Create saved segments for sources such as chatgpt.com, perplexity.ai, claude.ai, and gemini.google.com to monitor citation-driven sessions separately from traditional SEO traffic.
Most teams also correlate these spikes with branded query growth inside Search Console after major AI citations appear. That’s often the earliest signal that GEO is compounding before referral volume becomes statistically significant.
Where to Start This Week
If this is new territory, prioritize in this order:
- Search your top five keywords and count how many of the top 20 results mention your brand. That number is your current AI visibility baseline, your baseline before any off-site work begins.
- Explicitly allow PerplexityBot, ChatGPT-User, and other AI crawlers (full list in the Citation Stack Audit below). Make a deliberate, documented decision on GPTBot.
- Add FAQ content blocks to your top five commercial pages. Content structure matters more than schema markup alone.
- Ensure your G2 profile is active and has reviews from the last 90 days.
- Rewrite the introduction of your top three pillar pages to put the direct answer in the first 100 words.
These five actions address all three stack layers and require no budget, only time and editorial discipline.
Agentic Search
Preparing for Agentic Search. Google is rolling out browser-based AI agents that analyze DOM structure, screenshots, and accessibility trees to complete tasks such as booking reservations or comparing product specifications. If your site relies on complex JavaScript navigation, hidden forms, or unclear CTAs, agents may fail to complete tasks even if your content is perfectly citable. Follow agent-friendly UX practices: semantic HTML, accessible forms, clear product identifiers, and structured data for actions. (Google)
Conclusion
Being ranked but not cited makes you invisible to buyers who act on AI recommendations. The citation stack, memory, retrieval, and citation quality explain the gap between brands that appear in AI responses and brands that don’t. The gap is engineerable, measurable, and closable.
Many marketing teams have not yet documented a strategy for AI-driven search visibility. Early movers in AI search optimization are currently building measurable advantages, and since Google treats this as an extension of SEO, the investment compounds across both traditional and generative search experiences.
Brands that systematically address memory, retrieval, and citation quality are more likely to appear consistently in AI-generated responses.
Citation Stack Audit: Prioritized by Impact

Phase 1 — Foundation:
Entity + Technical. Make your brand recognizable and crawlable before anything else.
- robots.txt — crawler access by platform: Google Search (AI Overviews, AI Mode): Googlebot — same crawler as standard search; no separate AI crawler needed Gemini training only: Google-Extended Other AI platforms: GPTBot, OAI-SearchBot, ChatGPT-User (OpenAI); ClaudeBot, Claude-SearchBot (Anthropic); PerplexityBot
- Organization schema with sameAs links to Wikipedia, Crunchbase, LinkedIn, and G2
- Semantic drift check: entity definition consistent across all platforms
- Page speed under 2 seconds
- IndexNow integration for instant Bing indexing (feeds Copilot and Perplexity real-time retrieval)
Phase 2 — Authority:
Off-Site Presence: Build the 91% that your own site cannot capture.
- Earned media in 5+ AI-cited publications
- Reddit presence in 2–3 relevant communities
- G2 profile active with reviews from the last 90 days
- Original research published with citable statistics
Phase 3 — Extraction:
Content Structure: Make your content the most quotable passage available for each query.
- FAQ content blocks on the top 5 commercial pages
- BLUF answer in the first 100 words on pillar pages
- Comparison tables on the top 3 product pages
- Acknowledged trade-offs in product positioning (for Claude)
Nova Express Resources
Want to go deeper? Here are related guides from our team:
Strategy & Psychology:
- Brand DNA: The Missing Piece Between Your Brand and AI
- How AI Search Decides Which Brands to Show in Answers
- What Is an AI Marketing Agent?
- AEO vs SEO vs GEO: What’s the Difference and Where to Start in 2026
- What Competitor Analysis Reveals About You (Not Just Them)
- What Is Generative Engine Optimization?
Tools & Tactics:
- AI Tools for Marketers in 2026
- NotebookLM for Marketers
- Storytelling Elements for High-Converting Marketing Campaigns
About the author
Serafima Osovitny is a marketing manager at Nova Express. Passionate about turning complex marketing tactics into simple, actionable guides, she shares insights about AI search visibility and generative engine optimization.
Explore her work at serafima.digital and follow her on X: @OSerafimaA








Leave a Comment